Free Law Project Re-Launches RECAP Archive, a New Search Tool for PACER Dockets and Documents
After months of development, we are thrilled to share a from-scratch re-launch of the RECAP Archive. Our new archive, available immediately at https://www.courtlistener.com/recap/, contains all of the content currently in RECAP and makes it all fully searchable for the first time. At launch, the collection contains information about more than ten million PACER documents, including the extracted text from more than seven million pages of scanned documents.
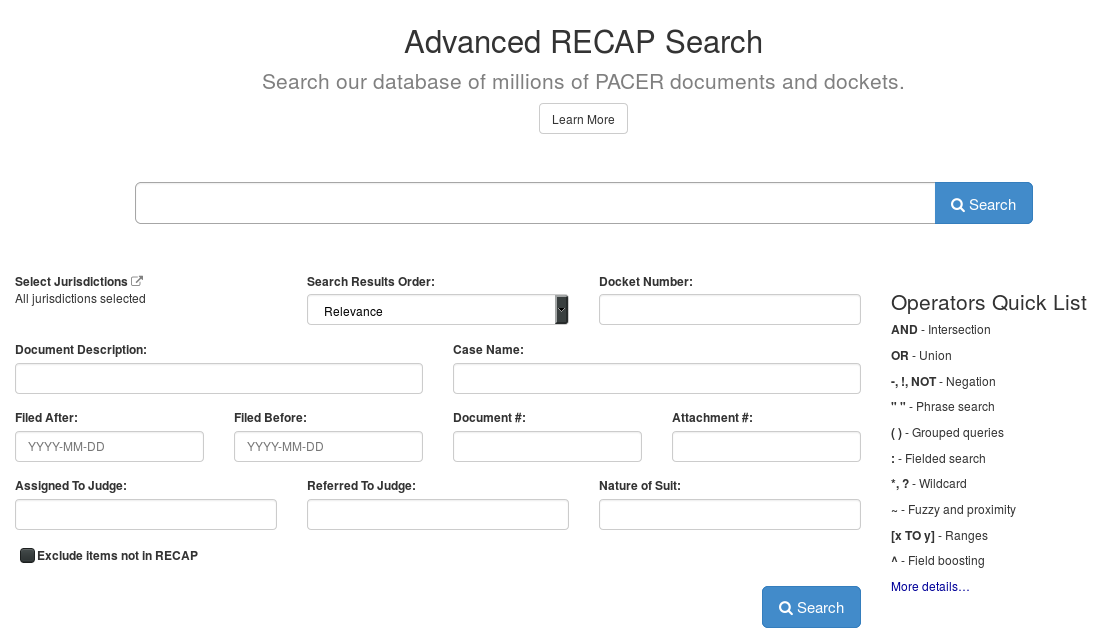
The new advanced search interface for the RECAP Archive.
The search capabilities of this new system empower researchers in new ways. For example:
-
It is now straightforward to search for certain types of documents within our archive of PACER documents. This makes it easy to find examples of motions to dismiss, summary judgements, or any other type of document.
-
Researchers can filter by nature of suit, case name, jurisdiction, cause, or one of a number of other fields. Ever wish you could look for examples of certain kinds of documents in your jurisdiction or topic area? Now you can.
-
It is now possible to do full-text search within all the documents in a case that are in the RECAP Archive. This feature is particularly powerful in large cases containing thousands of documents. For example, one of the largest cases we have is the Deepwater Horizon case, related to the BP Oil Spill a few years ago in the Gulf of Mexico. Here are all the times in that case (that we know about) where the word "tourism" is mentioned.
Beyond the powerful search capabilities we have built into this tool, this new archive makes a variety of tasks possible that were difficult or impossible before. For example:
-
Every document and every docket in the RECAP Archive now has a link. This makes it much easier to share PACER documents. Rather than telling a colleague to go to a certain PACER website, search for a certain case, then look for a certain document, now you can simply share a link.
-
All documents have page counts in their metadata. This means that before you even open an item, you know what to expect. It also allows fascinating research. For example, we now know that the average length of a PACER document is 9.1 pages, and the average length of a summary judgement is 18.9 pages.
Privacy Balance
Privacy of personal information has always been important to us at Free Law Project and in conjunction with this launch, we are refining the privacy rules we use when handling PACER documents. The new privacy rules are as follows:
-
All PACER documents are available in our search results and our website, and will be available in our APIs and bulk data when those features are ready. However, PACER documents are not available to public search engines like Google and Bing.
-
PACER dockets are generally available to search engines, but with two exceptions. First, if a request is made by a party in a case to make it private, we consider doing so. Second, any bankruptcy case with fewer than 500 items is private by default. There are innumerable personal bankruptcy cases, so we use this threshold to gauge the importance of the case.
-
Finally, if a docket or document in RECAP is subsequently sealed, we will defer to the court, and remove that item from RECAP.
We see the rules above as a starting point, and we will be refining these rules as we hear more from our stakeholders.
What's Next?
As we move forward with our PACER and RECAP initiatives, we see a number of next steps:
-
In the next few months, we will be launching a PACER/RECAP data service. This service will help journalists and researchers acquire and understand PACER content. Already we are identifying and working with researchers to refine this service.
-
We are planning to download all free opinions and orders from PACER so that we can make them available in this search interface, our API, and our archives. We believe this is an important step in fixing the PACER problem.
-
We will soon be launching an API for the data that is currently in this archive so that it can be downloaded by researchers and organizations. We are still investigating how to provide this service at a cost that is true to our mission and fair to our users. If you are a stakeholder that will be using this data, we welcome hearing your ideas for how a fair system could be created.
-
After the first API is launched, we will be developing a RECAP Clearinghouse that allows researchers and organizations to use our API to get content from PACER, whether we have it or not. The Clearinghouse will work similar to the RECAP extensions, except it will provide an API and will visit PACER on your behalf.
For example, in the case that we have a document, the clearinghouse will provide it to you for free. In the case that we do not, the API will use your credentials to purchase the document, and then will save a copy for future users to receive for free.
If you are a researcher, journalist or organization that would use a tool like this, please get in touch.
-
We will soon be running our citation extractor across the RECAP Archive to identify citations to opinions in our collection so that they can be analyzed and made into links.
-
A few details are not quite ready in this tool: Party information is not searchable, and alerts and RSS feeds for dockets are not yet in place. We will be adding these features as soon as possible, but decided to launch today so that we could begin getting feedback. As always, get in touch if you are interested in volunteering to help develop these features.
Wrapping Up
We believe that this new search tool and the roadmap presented above will bring a sea change in how people think about PACER. Creating an archive for all free PACER opinions and a clearinghouse for new content should quickly create a large and useful collection of PACER content. This will enable researchers, journalists, and organizations to focus their efforts where it matters --- creating new research, identifying and telling important stories, and innovating the legal marketplace. We hope you will join us in this effort, and that if you find these services and tools valuable, that you will support our work with a donation.
